



Par Nasreddine Menacer Docteur en robotique | Professeur assistant à aivancity
Un service SaaS (Software as a Service) est une application accessible en ligne, sans installation locale, généralement via un navigateur. Des outils comme Google Workspace, Salesforce, Notion ou Stripe en sont des exemples courants. Ce modèle s’est imposé dans la majorité des organisations, au point que l’infrastructure logicielle d’une entreprise repose aujourd’hui sur un ensemble de services interconnectés, souvent opérés par des fournisseurs distincts. Des rapports comme ceux d’Okta montrent qu’une entreprise utilise en moyenne près de 90 applications SaaS, avec des volumes nettement plus élevés dans les grandes structures.
Cette dépendance à un grand nombre de services introduit une complexité structurelle. Une application ne fonctionne plus comme un bloc isolé, mais comme un assemblage de composants distribués : APIs externes, systèmes d’authentification, bases de données, services cloud, pipelines de données. Chaque composant évolue indépendamment, ce qui rend le système global sensible à des changements locaux.

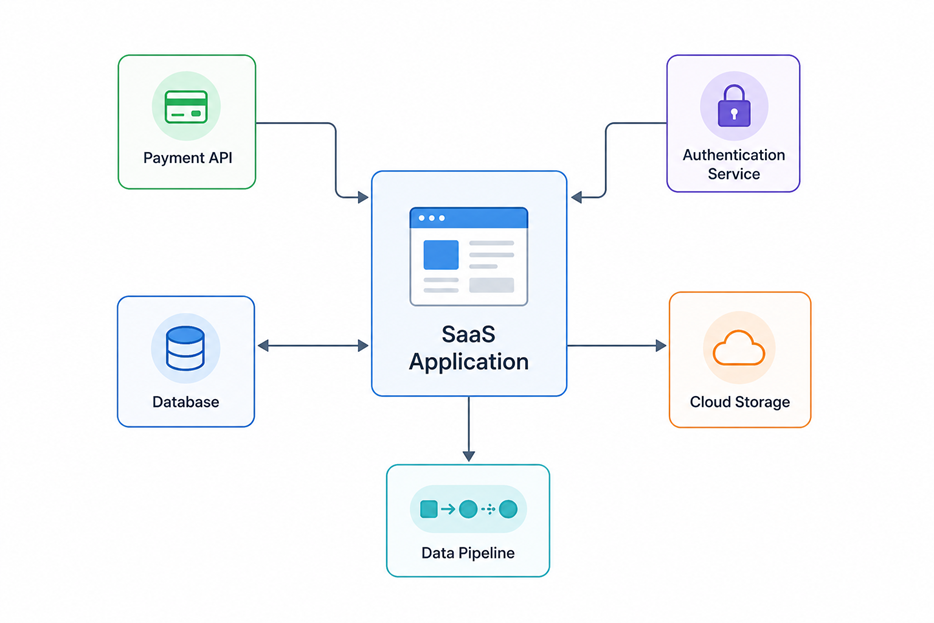
Dans ce contexte, les incidents proviennent fréquemment de ces interactions. Une API modifie un schéma de réponse, un endpoint est déprécié, un mécanisme d’authentification change, un service devient plus lent et déclenche des timeouts en cascade. Le code applicatif reste inchangé, mais le comportement du système ne correspond plus à ce qui était attendu.
Le traitement de ces incidents repose encore largement sur une intervention humaine. Un développeur analyse les logs, identifie le point de rupture, formule une hypothèse, teste un correctif et valide le résultat. Ce processus est maîtrisé, mais il reste entièrement réactif.
Dans le même temps, l’intelligence artificielle s’est imposée dans de nombreux usages opérationnels. Elle est utilisée pour générer du code, analyser des données, assister des décisions. Il est donc légitime de se poser la question suivante : si ces modèles sont capables de produire du code et d’interpréter des situations techniques, pourquoi ne pas les utiliser pour intervenir directement dans la maintenance des systèmes ?
Pour répondre à cette question, il faut préciser ce que font réellement ces modèles.
Intégration des modèles génératifs dans des architectures agentiques
Les modèles de langage utilisés aujourd’hui sont des modèles autoregressifs qui génèrent une séquence de tokens en maximisant une probabilité conditionnelle. Leur rôle consiste à produire une sortie à partir d’un contexte donné. Ce contexte inclut à la fois l’entrée utilisateur et un ensemble d’instructions définies en amont, souvent sous la forme d’un prompt système. Ce cadre détermine le comportement du modèle, qui reste limité à une tâche de génération. Un modèle génératif, utilisé seul, ne dispose ni d’un accès à un environnement externe ni d’une capacité d’action. Il produit une réponse, puis s’arrête. Cette limitation explique pourquoi son utilisation directe ne permet pas de gérer un processus de maintenance.

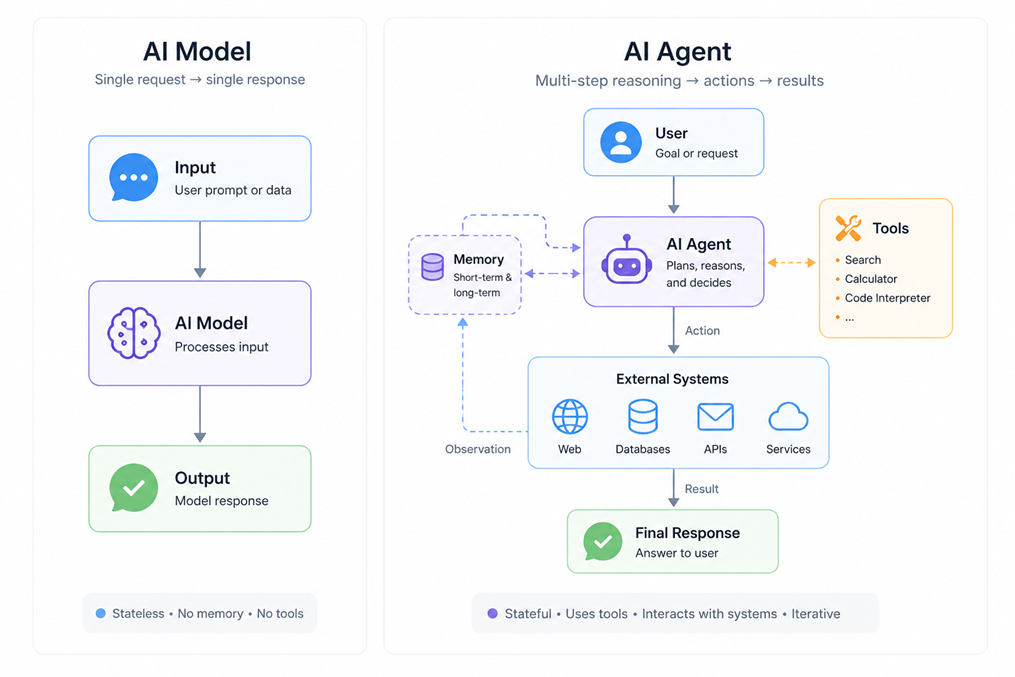
Le passage à des agents repose sur une intégration différente. Le modèle est placé au sein d’un système qui lui fournit des moyens d’interagir avec son environnement. Il peut accéder à des outils, exécuter des requêtes, lire des logs, interroger des APIs, modifier un état dans un cadre contrôlé.
Le fonctionnement repose sur une orchestration explicite. Une tâche est décomposée en plusieurs étapes, chacune correspondant à un appel au modèle avec un objectif précis. Cette séquence, souvent implémentée sous forme de prompt chaining, permet de structurer le comportement global. Le modèle intervient pour analyser, décider d’une action, interpréter un résultat, puis alimenter l’étape suivante.
Dans ce cadre, l’agent ne repose pas sur une intelligence autonome au sens fort, mais sur une combinaison de règles, d’outils et de décisions locales prises par le modèle. Cette organisation correspond bien à des tâches comme la maintenance, qui nécessitent une analyse progressive et une interaction avec plusieurs sources d’information.
Traitement des incidents dans les systèmes SaaS par des agents
La maintenance logicielle repose sur des opérations structurées. Lorsqu’un incident survient, l’analyse commence par l’examen des logs et des métriques, se poursuit par l’identification d’un point de rupture, puis par la formulation et la validation d’une correction.
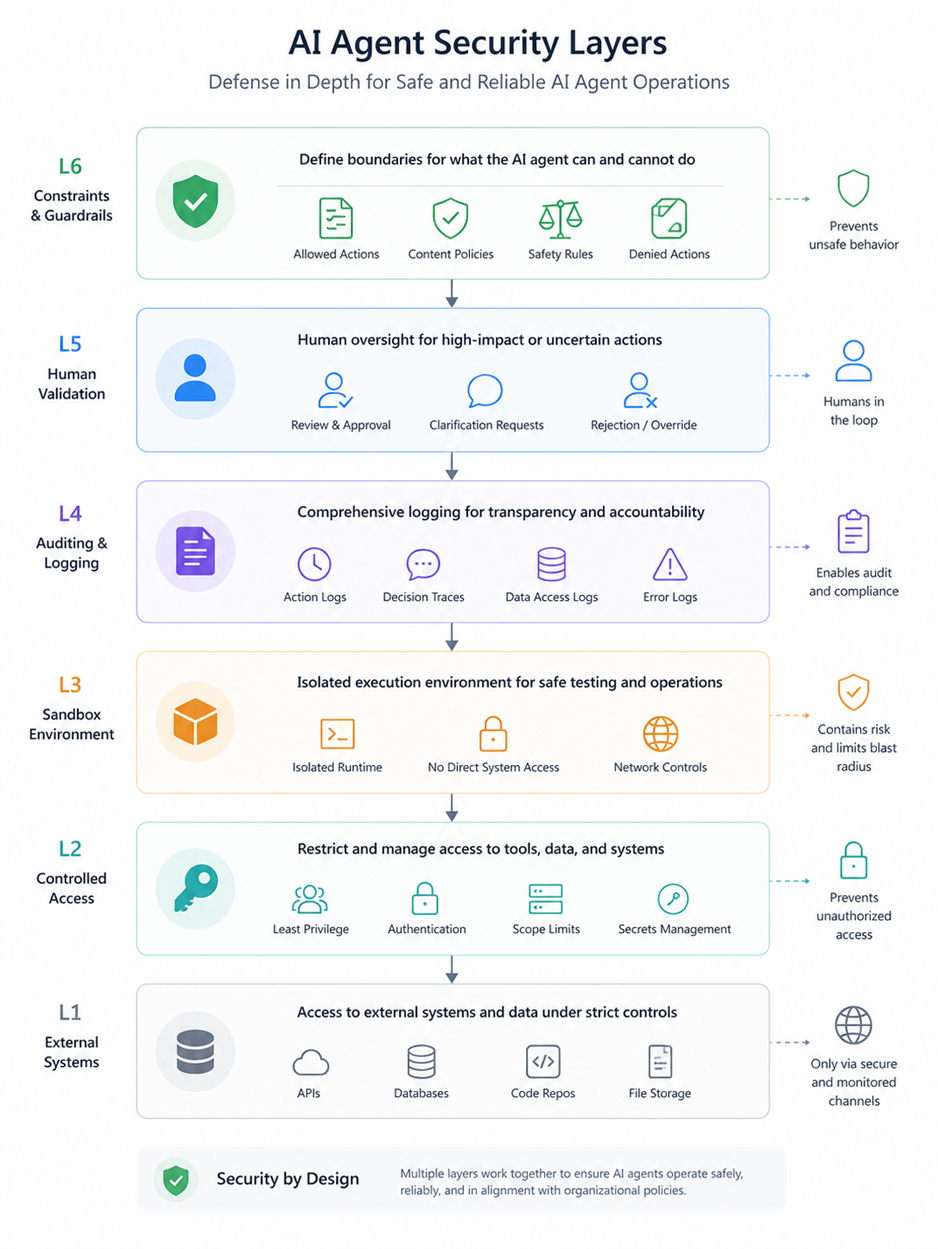
Ce type de processus peut être partiellement pris en charge par un agent, à condition de lui fournir un accès contrôlé aux éléments nécessaires : logs, traces, documentation, code, environnement de test.
L’architecture d’un tel agent repose généralement sur plusieurs composants :
- Un orchestrateur, qui définit la séquence des étapes
- Un registre d’outils, qui expose les actions possibles (lecture de logs, appel d’API, exécution de tests)
- Un modèle de langage, utilisé pour analyser et décider localement
- Une mémoire de travail, qui conserve les états intermédiaires
- Un environnement isolé, permettant de tester les modifications

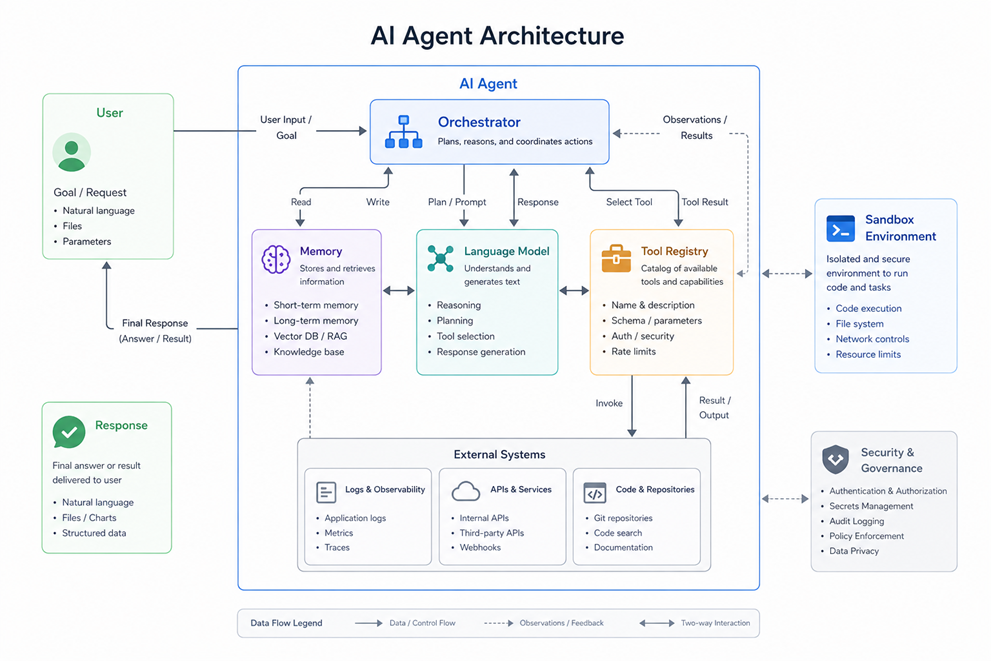
Le déroulement d’un traitement d’incident suit alors une séquence explicite. L’agent récupère le contexte, identifie un point de défaillance probable, propose une ou plusieurs hypothèses, puis teste des corrections dans un environnement contrôlé. Les résultats sont analysés avant toute décision d’application.

Cas concret : modification d’une API de paiement

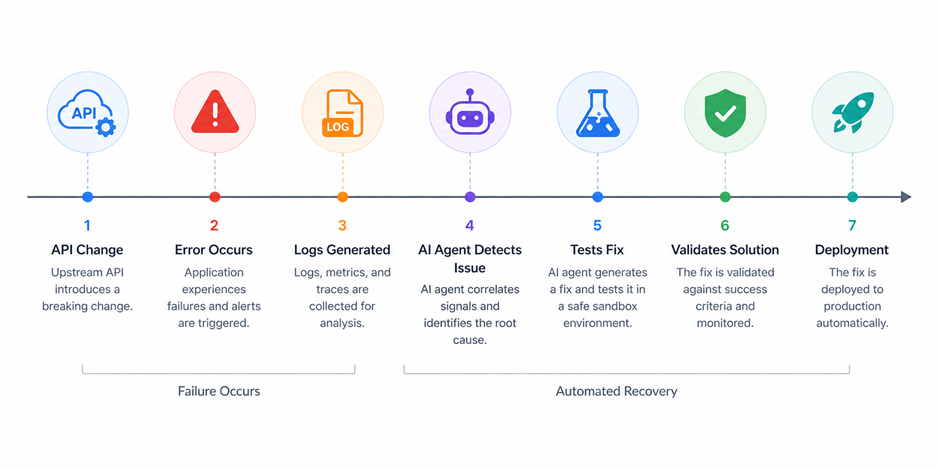
Un service SaaS utilise une API de paiement pour traiter des transactions. Suite à une mise à jour côté fournisseur, le champ amount dans la réponse JSON change de type et passe d’un entier à une chaîne de caractères.
Dans le code existant, ce champ est directement utilisé dans une opération numérique, ce qui provoque une erreur. Les logs montrent une exception liée à un type inattendu, et certaines transactions échouent.
Dans un fonctionnement classique, un développeur analyse les logs, identifie l’origine du problème, modifie le parsing pour convertir explicitement la valeur, puis déploie un correctif.
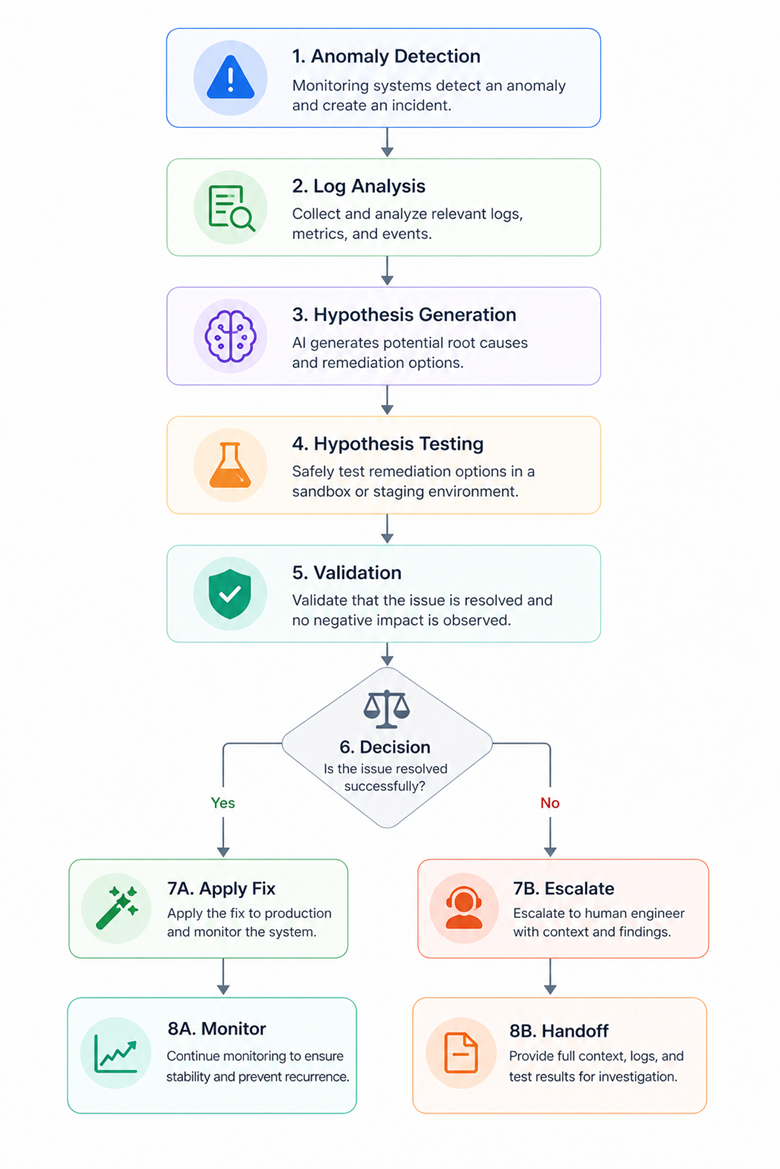
Avec un agent intégré, la séquence peut être la suivante :
L’agent détecte une augmentation anormale des erreurs sur une route spécifique. Il récupère les logs associés et identifie une exception liée au type d’un champ. Il extrait des exemples de réponses API récentes, les compare à des réponses archivées, et constate une différence de structure.
À partir de cette observation, il formule une hypothèse sur la cause de l’erreur, puis génère une modification du code ou du mapping de données. Cette modification est testée dans un environnement de staging, avec des cas de test représentatifs. Si les tests passent et que le flux redevient fonctionnel, le correctif est proposé.
À ce stade, deux options existent : soit le système applique automatiquement la correction dans un périmètre limité, soit il requiert une validation humaine avant déploiement.
Conditions d’utilisation et limites des agents en maintenance logicielle
Il est techniquement possible d’intégrer ce type d’agent dans un système de production et d’automatiser une partie de la maintenance, y compris sur des incidents réels. Les briques nécessaires existent déjà : modèles génératifs, outils d’orchestration, environnements isolés, pipelines de test.
En revanche, il serait imprudent de laisser un agent agir sans contrôle.
Un modèle génératif produit des solutions plausibles, sans garantie de correction globale. Dans un système complexe, une modification locale peut avoir des effets de bord difficiles à anticiper. La question n’est pas de savoir si l’agent peut se tromper, mais dans quelles conditions cette erreur est contenue. Une architecture robuste impose donc des contraintes explicites :
- Limitation des actions possibles (lecture, écriture, modification ciblée)
- Isolation des environnements de test
- Validation humaine pour les changements impactant la production
- Journalisation complète des actions
- Possibilité de rollback systématique
Dans ce cadre, l’agent devient un outil d’accélération du diagnostic et de la correction, sans remplacer la responsabilité humaine sur les décisions critiques.

Vers une Intégration progressive d’agents dans les systèmes logiciels
L’intégration d’agents dans la maintenance s’inscrit dans la continuité des mécanismes déjà en place. Les systèmes utilisent depuis longtemps des formes de résilience automatisée, comme les retries, les circuits breakers ou l’auto-scaling.
Les modèles génératifs apportent une capacité supplémentaire, en permettant de traiter des situations qui ne sont pas entièrement définies à l’avance, grâce à une interprétation du contexte.
Dans la pratique, cela permet de déléguer une partie de l’analyse et de la correction des incidents, dans un cadre encadré par des règles et des mécanismes de contrôle.
À moyen terme, les architectures SaaS devraient intégrer des agents dédiés à la maintenance. Leur rôle consistera à intervenir sur le diagnostic et certaines corrections, avec un impact direct sur les délais d’intervention et les coûts opérationnels.
Pour les équipes, cela réduit le temps consacré aux incidents récurrents. Pour les entreprises, cela renforce le positionnement produit. La capacité à identifier rapidement un problème et à enclencher une correction, avec un système qui surveille en continu, constitue un argument concret en termes de fiabilité et de temps de résolution.
Dans ce contexte, l’enjeu reste la rapidité de détection et de traitement des incidents, appuyée par une surveillance continue et des mécanismes d’intervention encadrés. Ce niveau de réactivité fait partie des critères utilisés par les clients pour évaluer un service.





Maîtrisez l’IA Agentique
avec Claude Cowork
Passez de l’IA conversationnelle à l’IA opérationnelle. 2 jours pour automatiser vos tâches complexes — aucune compétence technique requise.
Bibliographie
Bouzenia, I., Devanbu, P., & Pradel, M. (2025). RepairAgent: An Autonomous, LLM-Based Agent for Program Repair. Proceedings of the IEEE/ACM International Conference on Software Engineering.
Jin, H., Huang, L., Cai, H., Yan, J., Li, B., & Chen, H. (2024). From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future. arXiv preprint.
Liu, J., Wang, K., Chen, Y., Peng, X., Chen, Z., Zhang, L., & Lou, Y. (2024). Large Language Model-Based Agents for Software Engineering: A Survey. arXiv preprint.
Yang, J., Jimenez, C. E., Wettig, A., Lieret, K., Yao, S., Narasimhan, K., & Press, O. (2024). SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. Advances in Neural Information Processing Systems.
Xia, C. S., Deng, Y., Dunn, S., & Zhang, L. (2024). Agentless: Demystifying LLM-based Software Engineering Agents. arXiv preprint.
Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., & Narasimhan, K. (2024). SWE-bench: Can Language Models Resolve Real-World GitHub Issues? International Conference on Learning Representations.
OpenAI & Princeton NLP. (2024). SWE-bench Verified: A Human-Validated Benchmark for Real-World Software Engineering Tasks.
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. International Conference on Learning Representations.
Microsoft Research. (2025). AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Cloud Operations. arXiv preprint.
Yehudai, A., Eden, L., Li, A., Uziel, G., Zhao, Y., Bar-Haim, R., Cohan, A., & Shmueli-Scheuer, M. (2025). Survey on Evaluation of LLM-based Agents. arXiv preprint.
Okta. (2024). Businesses at Work 2024. Okta Research Report.
Zhang, Q., et al. (2025). Advancements in Automated Program Repair: A Comprehensive Review. Knowledge and Information Systems.